
When flows split: An introduction to concurrent programming
A computer program is a nicely ordered flow of instructions, executed one after the other from start to finish… Except when it is not. We often wish to split this flow. Let’s see why and when to do it.
So, what’s concurrent programming?
The traditional way of writing programs is to express them sequentially. When one input is received, an output is produced by executing a number of tasks in order. Then the program becomes ready to process the next input, over and over again.

Figure 1 – sequential computing
This way of working matches how machines with a single processing core work. A single processor can only do one thing at a time, so this is the most straightforward method to program on it.
There are drawbacks, however. If any of the tasks needs to wait for something, say, a peripheral or the network, then the processor will remain idle during this waiting period. Processing of further inputs will be delayed, thus reducing the overall system effectiveness.
Ideally, processor time could be spent advancing one task for the next input while the processing of the previous input is waiting. This way a shared resource – the processor – could be used efficiently by different computations. To the human observer, both computations would seem to be performed simultaneously, while in reality they were being interleaved.
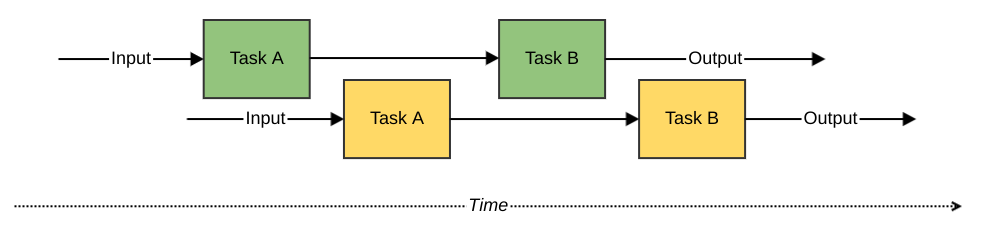
Figure 2 – concurrent computing
We just defined concurrent computing while barely noticing it. Any two computations are concurrent whenever they share a common resource. They don’t occur at the same exact moment in time, but their lifespans overlap. Concurrent programming is the set of programming techniques that allow us to write programs that work in this manner.
The moment in time when computations happen is a subtle but important detail that allows us to distinguish between concurrent and parallel computing. With parallel computing, computations don’t always share resources and overlap at one or more moments in time.
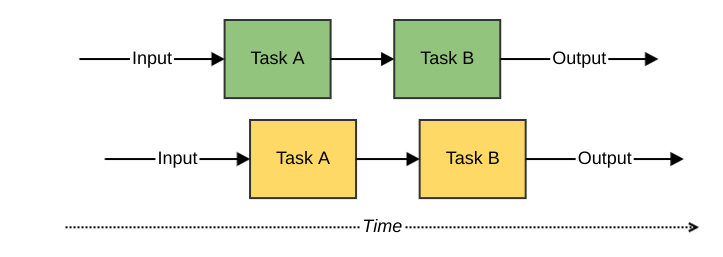
Figure 3 – parallel computing
It follows that we need to employ different physical processors in order to actually run some parallel computing. Otherwise, such computations would not be parallel but concurrent. Multi-processor computers and distributed systems are examples of computational hardware that is capable of executing parallel computations. Parallel programming is thus a specialization of concurrent programming, using similar techniques, focused on ensuring that computations occur at the same physical time.
Which operations fit a concurrent model best?
Going back to our task that needs to wait for a resource, we concluded then that processing time was not being used efficiently. It is therefore logical that operations that need to wait for something else are prime candidates to be executed concurrently. It does not make sense to run them exclusively in parallel because resources will be wasted anyway whilst barely improving throughput.
Tasks that don’t wait are perfect candidates for parallelism. Think about data processing and mostly calculations. If it doesn’t need to wait nor share resources, then it will benefit the most from running in parallel.
For the remainder of this article, we will focus on concurrency instead of parallelism. The most common challenges fall within this category. This does not mean that nothing of what will be said applies to parallel computing; most of it also applies, however one must choose the correct supporting framework.
Preparing for concurrency
First and foremost, we must be sure that the problem at hand can be solved properly using concurrent programming. The initial step is to decompose the problem in a sequence of separate tasks. Once this is done, we need to determine if most of those tasks will spend a long time waiting for some resource or operation to complete, say, I/O. If this is the case, then we found ourselves a good candidate for a concurrent solution. The tasks that need to wait can do so while relinquishing their CPU time for the duration of the waiting period.
Concurrent programming models
Concurrent tasks need to exchange data amongst themselves like any other. This data needs a vehicle, which leads us to the two common concurrent programming models: shared memory and message passing.
Both are quite easy to understand. When concurrent tasks read and write objects in memory to exchange data, then the model being used is one of shared memory. Memory, in this sense, doesn’t necessarily mean volatile memory. It can also be a file system where concurrent tasks exchange data inside files, for example.
With message passing, concurrent tasks are sending and receiving well defined chunks of data through a communications channel, regardless of their locality. Examples of such channels could be HTTP, EMS, shared sockets, etc.
Typically, shared memory models are used within the program itself, whilst message passing is used between different programs that may even be located in different computers.
Concurrent programming is hard
Concurrency is all about resource sharing. The most evident – and problematic – kind of sharing is writing to a shared data location. A classic example is the bank account deposit problem. If two tasks want to deposit one euro in the same bank account at the same time, it is possible for money to be lost depending on the way how the independent deposit steps are ordered. This is a problem known as a race condition, whereby the outcome is dependent on which concurrent operation finishes first.
Other well-known problems are starvation and deadlocks, which can occur when there are multiple tasks sharing a finite set of resources. Resources may be claimed by all tasks in such a way that each task still lacks resources to continue: no task makes any progress, which is a deadlock. If only a subset of tasks is blocked from continuing, we say that these tasks are being starved. The dining philosophers problem [2] is a good example of a system study where both problems may happen, depending on the solution chosen.
All this goes to show that concurrent systems possess non-deterministic characteristics, i.e., the time and order of operations is not always the same and depends on external conditions. Think about load on a web shop during a sale. The timing of operations is widely different during such peak times. Some defects (like the deposit problem) may cause trouble during these periods and remain harmless the rest of the time. These can be very hard to detect, fix, and test for.
Humans have a hard time wrapping their heads around parallel flows. That being said, [1] helps with further understanding of these basic problems related to concurrency.
Implementation styles
The basic premise of concurrency is the interleaving of tasks (see figure 2). In order to accomplish this on only one computer, some foundation must exist through which such interleaving becomes possible. A construct called a thread was thus developed.
A thread is the smallest unit of execution that can be managed by a hardware platform or operating system. From a physical point of view, one hardware thread corresponds to one CPU core. At the operating system level, threads (also known as software threads) are managed by a scheduler, which contains a mechanism that executes several threads alternatively on the same hardware thread.
This is how we can run a very high number of programs on the same computer concurrently: each program correlates to at least one thread. Then these threads share a reduced number of hardware threads, taking their turns to move ahead in doing their jobs. If this mechanism for alternating between threads did not exist, we would only be able to run concurrently as many programs as the number of CPUs in the computer.
The alternation mechanism can be pre-emptive or cooperative. The former means that the scheduler is free to decide for how long it will allow a thread to run on a hardware thread, whereas the latter means that threads themselves decide when they are ready to yield CPU time. (Can you see how cooperative systems can be led into starvation?) The difference between pre-emption and cooperation is key when reasoning about concurrency.
Some platforms already support fibers, which can be seen as software threads that are scheduled cooperatively on the operating system threads. A second level of scheduling, or a higher level of abstraction, so to speak. These came into existence because they need less memory to save their state and execution takes less time to switch from one to the next, comparatively to threads.
Tools for concurrency in the JVM
Threads are implemented in the JVM as a direct correspondence to operating system threads. Their management can be simplified by using implementations of the ExecutorService interface, which decouples threads from runnable tasks. They also provide Future, which is an interface used to follow task execution state and obtain its result. Recent Java versions saw the rise of CompletableFuture, which expands on the concept of Future to ease task composition.
The difficulties that come along with resource sharing can be solved with judicious use of atomic variables, locks, specific concurrent implementations of collections, and synchronisation primitives. [3] provides a good overview on these basic constructs.
Upcoming versions of Java will bring new tools to the arsenal, including fibers.
Concurrency frameworks on the JVM
Naturally, we don’t want to rebuild the foundations every time we create a new concurrent application. There are several frameworks that we can use to build our applications upon. Some of these are:
Akka, a message-passing concurrency framework implementing the actor model. In this model, actors embody the logic necessary to process each message type and produce messages as result. [5] They can consequently run concurrently and independently from one another.
Vert.x, an event-driven framework, embraces the concept of reactive programming, which is about expressing behaviour as a reaction to external events. It also implements its own version of fibers, like “lightweight threads”.
RxJava allows us to express our concurrent flows as streams of objects or events. Leverages some functional programming concepts to simplify composition and expressivity of object processing pipelines. [4]
Kotlin is a language for the JVM which brings coroutines to the equation. Coroutines are a language construct which allows us to build concurrent tasks running cooperatively, much like fibers. Being built in the language itself, coroutines have the advantage of being concise and expressive.
Where to go from here?
This article was just a very quick overview of what concurrency is about, and how it can help with improving efficiency of specific problems. The interested reader will want to follow our reading suggestions to better understand the problems that concurrency brings and their solutions, as well as some frameworks designed to simplify the building of concurrent systems.
A second article about concurrency in the JVM addresses usage of coroutines in Kotlin: Concurrency in Kotlin: how coroutines make it easier.
Additional reading
[1] https://web.mit.edu/6.005/www/fa14/classes/17-concurrency/
[2] https://en.wikipedia.org/wiki/Dining_philosophers_problem
[3] https://docs.oracle.com/javase/tutorial/essential/concurrency/
[4] https://www.oreilly.com/library/view/reactive-programming-with/9781491931646/ch01.html
[5] https://doc.akka.io/docs/akka/current/typed/guide/actors-intro.html
